We compared LANDR and AI Mastering in sound quality.
Overview
We proposed an index that can objectively evaluate the mix MEI 20190207.
We compared the sounds mastering with AI Mastering and LANDR at MEI 20190207.
We found that AI Mastering has higher MEI 20190207 than LANDR.
AI Mastering has a tendency that the loudness range is larger than the LANDR, the Boominess is small, the Depth is small, and the Warmth is small.
* Since there are comparative sounds in the other people, please listen
Comparison method
Mastering various sounds with LANDR and AI Mastering and comparing the results with various indicators.
Sound to be compared
We chose the sound to be compared from the following mix evaluation data set. This mix evaluation data set includes multiple mixed audio for various songs and subjective evaluation results by multiple people for each mixed audio.
In the mix audio license, CC BY's, we selected the one with the largest loudness range for each song and the one with the lowest average subjective rating as the comparison target tone.
The reason is that it is easy to master without artifacts when the loudness range is large, and there is a mismatch of automatic mastering when the subjective evaluation is low.
Please see the GitHub repository below for a specific mix list.
index
MixEvaluationIndex20190207 (MEI20190207)
MixEvaluationIndex 20190207 (MEI 20190207) is an objective evaluation index of mixed audio constructed using subjective evaluation data of The Mix Evaluation Dataset. It is an evaluation index of mixed audio, but I think that it can also be used for evaluating mastering audio. It is intended for comprehensive evaluation. It is the main indicator in this comparison.
MEI 20190207 is calculated by the weighted sum of various indices. The original indices are the spread covariance matrix of the spectrum, the mean of the spectrum, Hardness, Dissonance. Simply put, I calculate it based on the shape of the spectrum, the dynamic range, the spread of space, the bandwidth of the attack, and the amount of distortion.
The mixed audio used for weight learning is all the mixed audio that is published in MixBrowser, with preview audio. Some preview audio was 404 Not Found.
Loudness
It is the loudness defined by ITU-R BS.1770. Depending on the platform to be delivered and how the user listens, it is highly likely that songs with loudness are more likely to be played with louder sounds as compared to other songs. It sounds better as you play with loud sounds.
If the sound quality is the same, the loudness should be large.
Other indicators
Loudness range, True Peak
Mastering setting
Please see GitHub below.
Comparison result
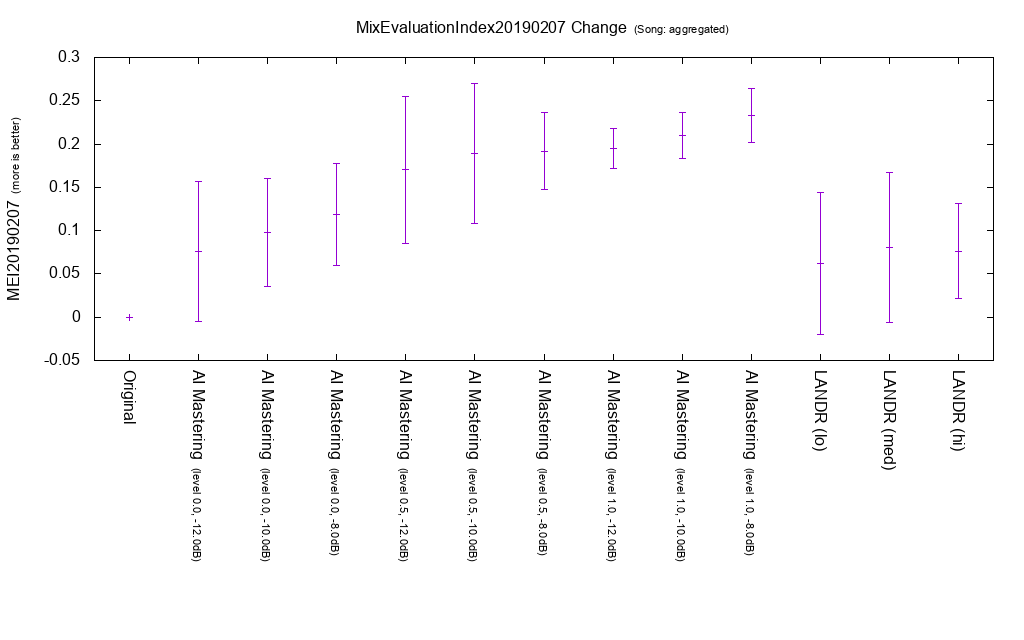
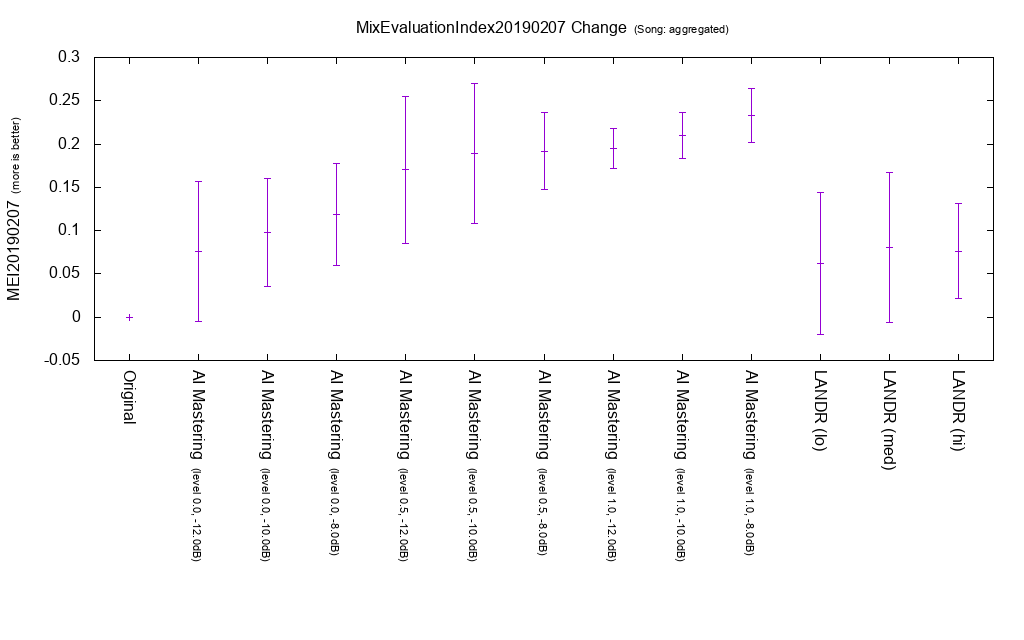
Change amount of MEI 20190207
It is the average of MEI 20190207 change with respect to the original for all songs. AI Mastering tends to have higher MEI 20190207 than LANDR.
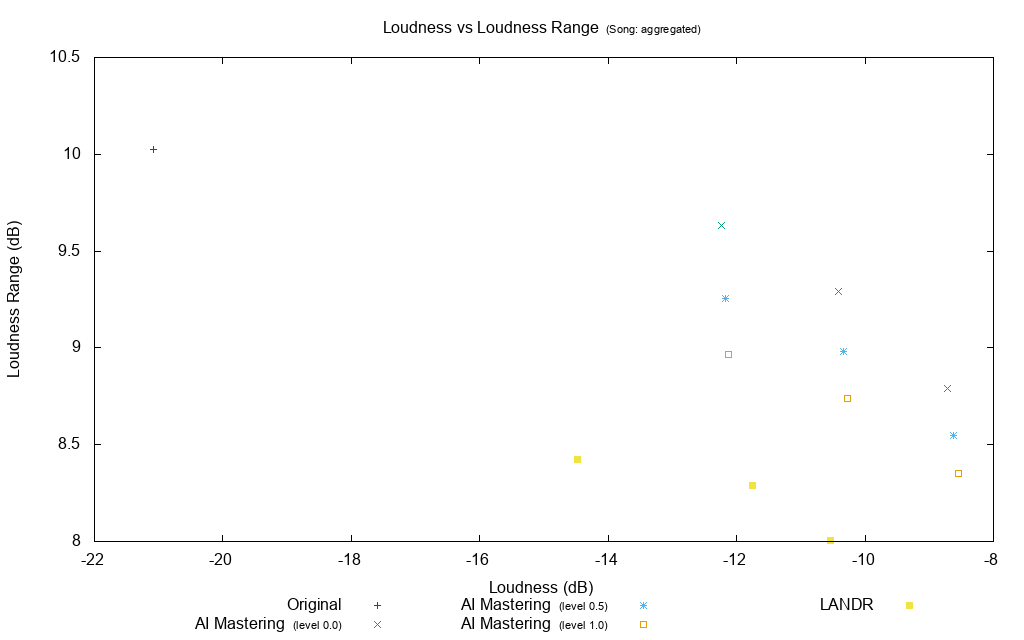
Loudness vs. Loudness range
I plotted the average of all songs in loudness and the average of all songs in loudness with a scatter plot. In general, the loudness and the loudness range are in a trade-off relationship, but the decrease in the loudness range when AI Mastering has a higher loudness than LANDR is small.
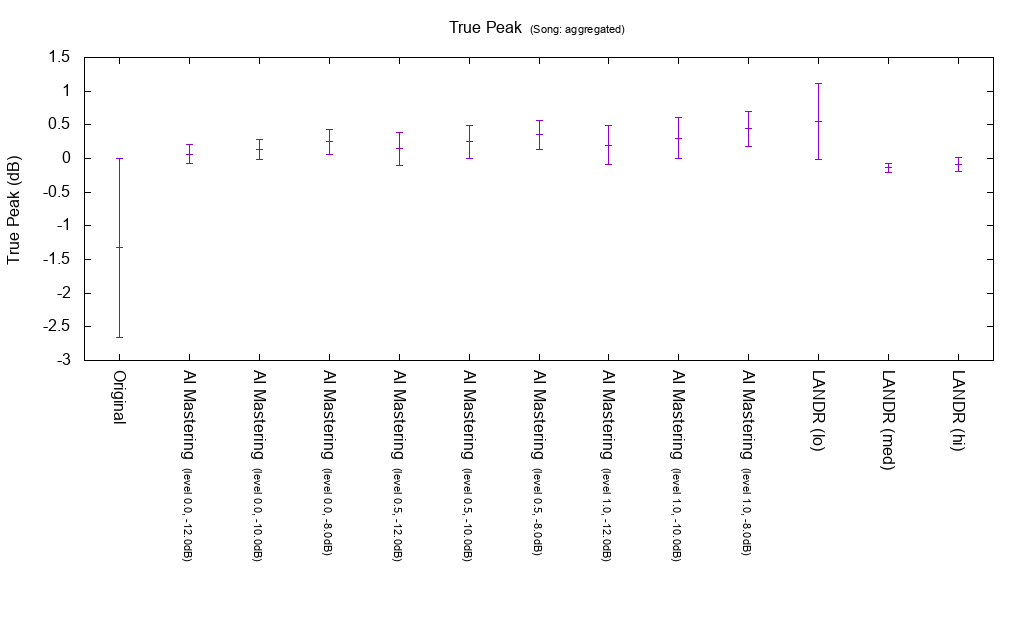
True Peak
True Peak (inter sample peak) is an average of all songs. If True Peak is larger than 0 dB, it may be distorted due to re-encoding etc, but there seem to be cases where both AI Mastering and LANDR exceed 0 dB. If you set Ceiling to True Peak in AI Mastering, you can prevent True Peak from exceeding 0 dB, so you can avoid degrading sound quality. LANDR is probably impossible to avoid because there is no such setting.
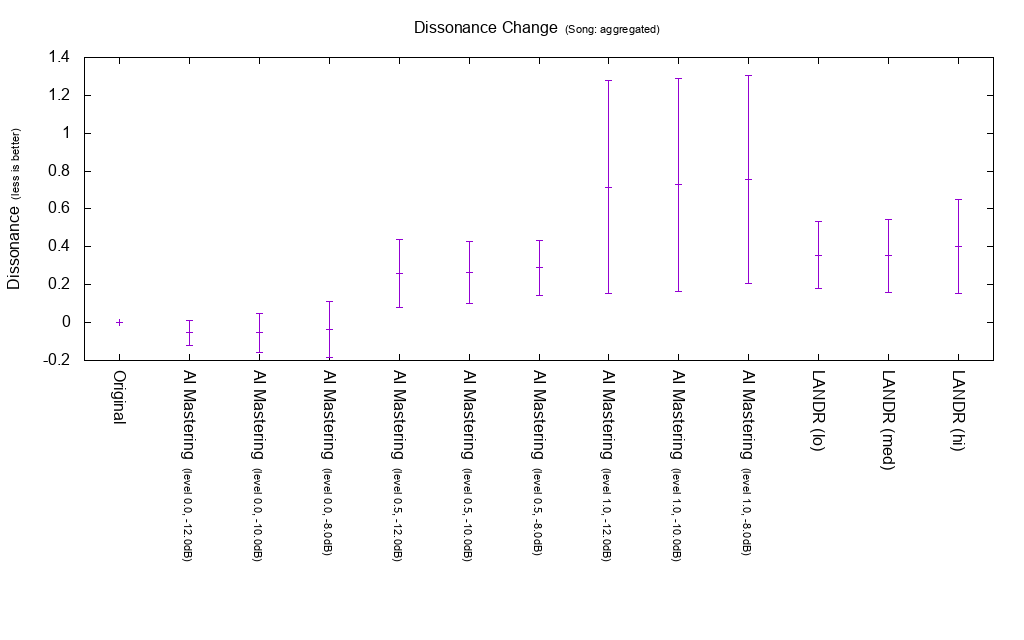
Change amount of Dissonance
Dissonance is an index to measure dissonance degree. It is used to calculate MEI 20190207, the lower the Dissonance, the higher the MEI 20190207.
If you set the mastering level to 1 in AI Mastering, Dissonance seems to increase. Setting the mastering level to 0.5 will result in an increase equivalent to LANDR.
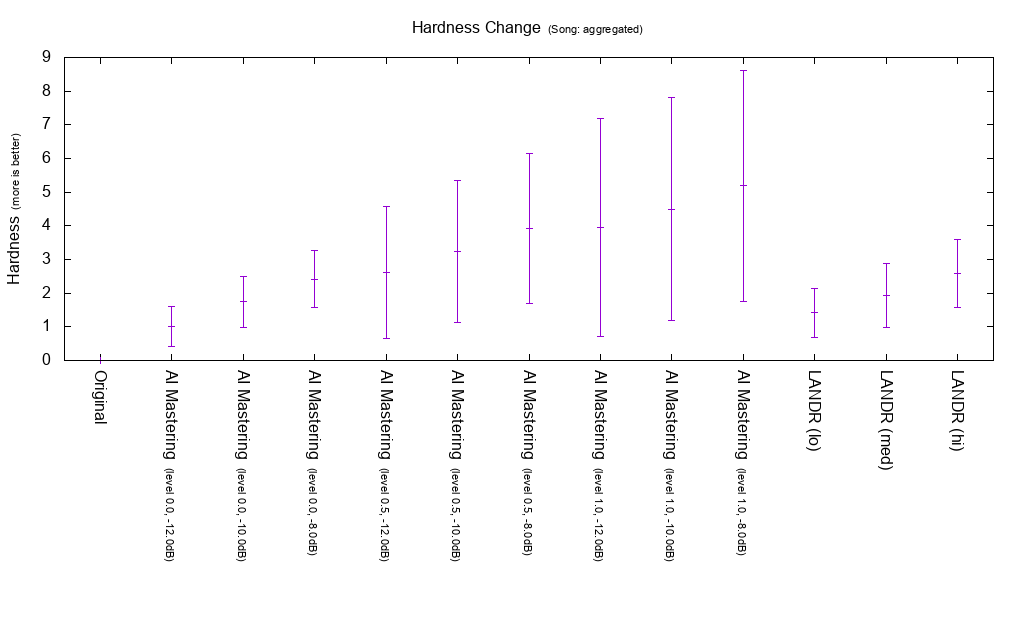
Change amount of Hardness
Hardness is an index to measure hardness of sound. It is used to calculate MEI 20190207, and the higher the Hardness is, the higher the MEI 20190207 is. Both AI Mastering and LANDR seem to increase Hardness.
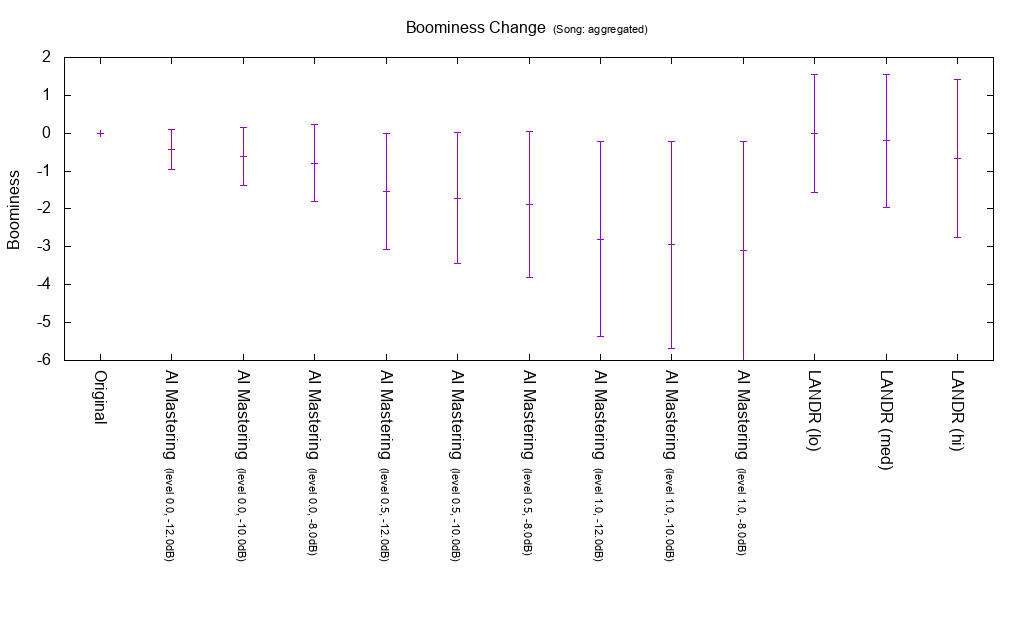
Changes in Boominess
Boominess is an index for Boomy degree. The contents are Booming Index proposed below. It is not used for calculation of MEI 20190207.
Booming index as a measurement for evaluation booming sensation
AI Mastering tends to lower Boominess.
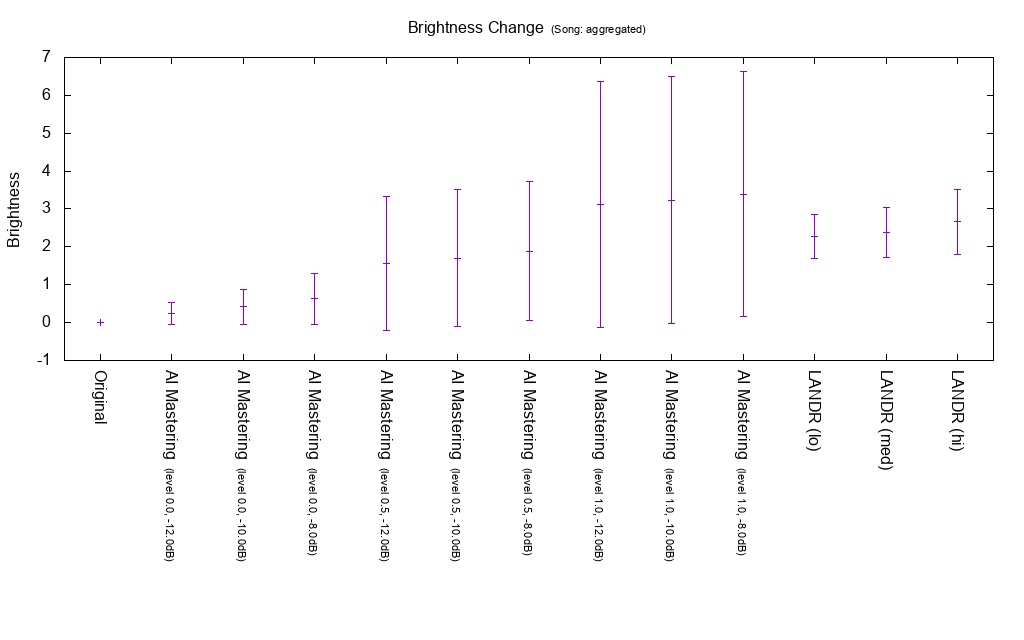
Change amount of Brightness
Brightness is an indicator of brightness. It is calculated by the linear combination of the logarithm of the energy ratio of the high frequency component to the total energy and the logarithm of Spectral Centroid. It is not used for calculation of MEI 20190207.
AI Mastering and LANDR tend to raise Brightness.
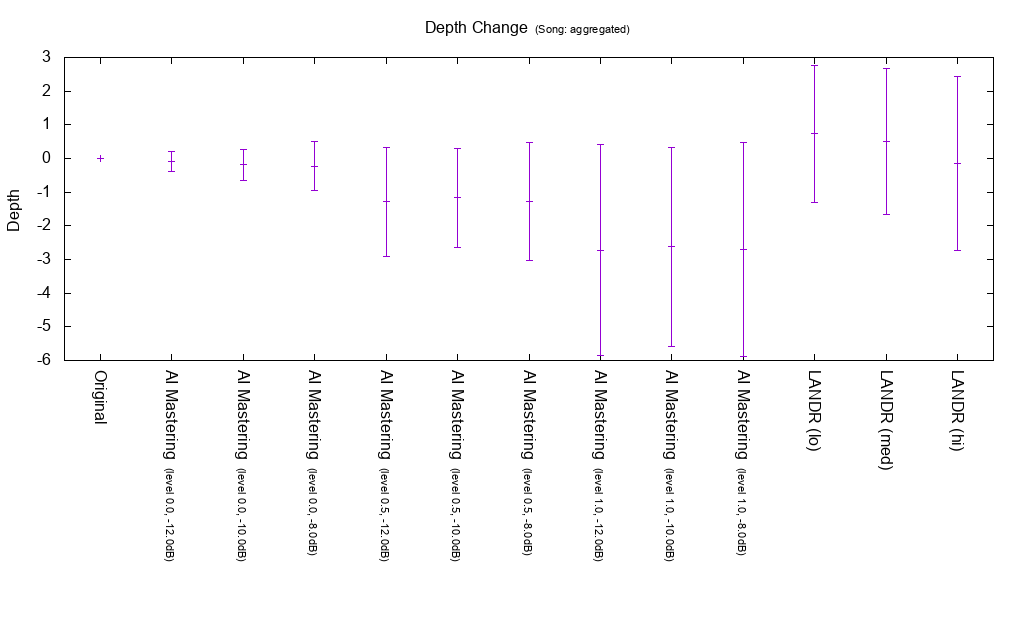
Change amount of Depth
Depth is an indicator of depth. It is defined in D 5.2 below. According to D 5.2, the depth has spatial meaning and frequency characteristic meaning, but this Depth index represents only frequency characteristic meaning. It is not used for calculation of MEI 20190207.
According to the definition, Depth will increase if there are many low frequency components. AI Mastering tends to lower Depth.
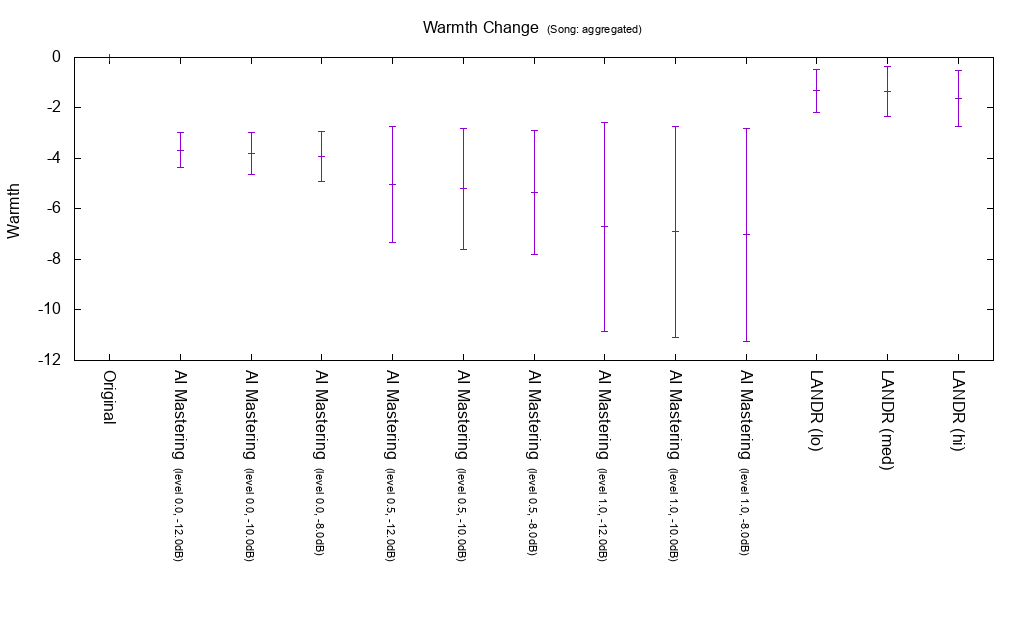
Amount of change of Warmth
Warmth is an indicator of warmth. The following is an implementation. It is not used for calculation of MEI 20190207.
AI Mastering tends to lower Warmth.
Comparison of sound after mastering
For each song, I picked up three of the original, LANDR with the largest MEI 20190207, AI Mastering with MEI 20190207 the biggest one. Since loudness is not aligned, please be careful of the bias due to the difference in volume.
All sound lists are below. Please try MEI 20190207 whether the high sound is really good sound. The license notation of each song is described under the audio directory of Github.
ai-mastering / mastering_comparison (Github)
In The Meantime
Original
AI Mastering Best MEI20190207
LANDR Best MEI20190207
Lead Me
Original
AI Mastering Best MEI20190207
LANDR Best MEI20190207
Not Alone
Original
AI Mastering Best MEI20190207
LANDR Best MEI20190207
Pouring Room
Original
AI Mastering Best MEI20190207
LANDR Best MEI20190207
Red To Blue
Original
AI Mastering Best MEI20190207
LANDR Best MEI20190207
Github
Detailed information is listed below.
ai-mastering/mastering_comparison (Github)
Note
What is written as "AI Mastering" on the graph or Github represents AI Mastering.
Summary
I compared LANDR and AI Mastering.