I'm very sorry, but recently I decided to make it free because it is difficult to support AI Mastering. We plan to distribute the free desktop version and open source the desktop version and the automatic mastering algorithm so that we can continue to provide it without support.
-Fixed the problem that the video and the sound deviated by the mastering of the video.
・ Improved noise reduction algorithm for iPhone version.
noise reduction
Improved the iPhone version of the noise reduction algorithm. If the noise volume fluctuates, I think now that noise reduction can be performed better than before.
The iPhone version of AI Mastering has been updated to v1.2.5.
Update summary
・ We speed up video upload and reduced transfer volume .
It is now possible to master videos encoded with H.264 and H.265 without re-encoding the video part .
Update Details
Conventional
In the past, all videos, including video, were uploaded to the server, and the server generated output videos. Therefore, when the capacity of the video part was large, upload and download took time . Also, in order to reduce the transfer volume, the smartphone sometimes re-encoded before uploading. Re-encoding took time and the image quality deteriorated .
Modified version
In the modified version, in the case of an MP4 movie made with H.264, H.265 + AAC, the video and sound are Demuxed (separated without degradation) on the smartphone side, and only the sound is uploaded and mastered. When mastering is over, download the sound after mastering, Mux the sound and video on the smartphone side and combine them with no degradation to create an output video.
For all other videos, upload the entire video as usual and make the output video on the server side. In this case, the video is re-encoded to H.264 + AAC MP4.
As a result, speeding up, high image quality, and transfer volume reduction were realized.
※ In the case of MP4 movie made with H.264, H.265 + AAC, the video part can not be seen when the one uploaded in the smartphone version is viewed in the PC version or in other smartphones. Please note.
iPhone version update method
It is possible to update from the following App Store link.
Request
If you have any comments or requests regarding the smartphone version, I would be happy if you can tell us.
Please wait for a while as Android is being supported.
We will show you how to translate Equalizer APO into Japanese.
What is Equalizer APO?
Equalizer APO is a Windows application that can apply various effects (EQ, compressor, VST) to various sounds (YouTube videos and game sounds) played from a PC.
The basic article on how to use Equalizer APO is described in the following article. If you do not know Equalizer APO, please refer to it.
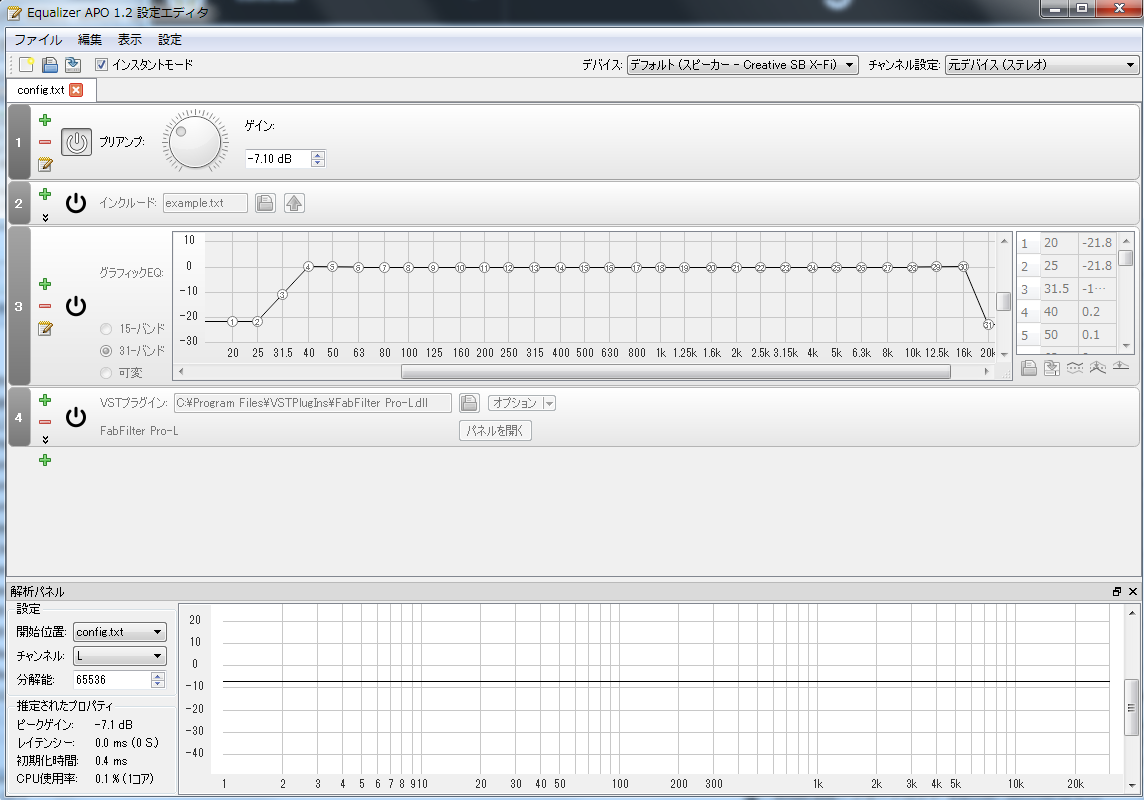
The version is described in the title part of Equalizer APO Configuration Editor. Make sure that the version is 1.2. If the version is not 1.2, please update Equalizer APO to the latest version.
2. Exit the Equalizer APO Configuration Editor
If the Equalizer APO Configuration Editor is running, it will exit.
4. Japanese localization with Equalizer APO Translator
Launch Equalizer APO Translator and press the "Apply Japanese Localization" button to perform Japanese localization. When finished, it is OK even if the Equalizer APO Translator is finished. If you get an error, please right-click the executable file and try "Run as administrator".
5. Start Equalizer APO Configuration Editor
Launch Equalizer APO Configuration Editor.
6. Set the language setting of Equalizer APO Configuration Editor to English
Set the language setting of the Equalizer APO Configuration Editor to English. It is difficult to understand, but if you set the language setting to English, it will be Japanese.
When Japanese localization is completed, it will be as follows.
I want to translate into other languages
Languages supported by the official Equalizer APO are English and German. If you want to translate Equalizer APO into languages other than English, German or Japanese, you may be able to respond by sending a translation of the translation part of the following file into the target language. However, please note that there is no guarantee that it can be supported.
It is the result of analyzing "be yourself" of "DÉ DÉ MOUSE" by AI Mastering.
Analysis result of “DD DÉ MOUSE” and “be yourself” by AI Mastering
Basic statistics
Loudness time series
spectrum
Spectrum distribution
Loudness histogram
How can I get the same sound pressure as "DÉ DÉ MOUSE" and "be yourself"?
According to the analysis results, the loudness of "be yourself" is -7.6 dB, so I think that it is better to set to a target sound pressure a little larger than that in AI Mastering and mastering.
Because the target sound pressure is high, the Ceiling setting is recommended "Peak" or "True Peak". "True Peak (15 kHz Lowpass)" is too conservative for clipping because it lowers the peak so that it does not clip if it is cut more than 15 kHz due to re-encoding, etc.
If you set "True Peak", it is recommended to set oversampling to 2x.
AI Mastering has been updated. A new mastering algorithm "v2" has been added.
New algorithm "v2"
Added new mastering algorithm "v2" to custom mastering. You can select the new algorithm "v2" and the conventional algorithm "v1" in the advanced option.
* "V2" is selected for One Touch Mastering (Easy Mastering).
Features of the new algorithm "v2"
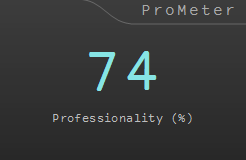
v2 masters so that "Proposity 2" goes up. Since the search performance of the mastering parameter is higher than v1 , "Prop2" rises with high probability.
It is also possible to specify a reference. When a reference is specified, mastering is made so as to approach the reference, not to raise "Prop. 2". You can not specify a preset like v1.
It includes processing to minimize the departure from the original sound quality, whether you specify a reference or not. In v1 there was a case that the sound quality changed extremely depending on the sound source, but it is relaxed.
The mastering level allows you to adjust how far away you want from the original sound quality.
Characteristics of conventional algorithm "v1"
v1 masters so that "Proposity" goes up. As we select the mastering parameters heuristically, the "pros" may not improve much.
Development history
Changing the mastering parameters of AI Mastering changes "Proposity" in various ways, but adjusting it to increase "Proposity" makes the sound better. Can you automate this? I received an opinion.
It is v2 that corresponds to this opinion. Since the search algorithm for mastering parameters is enhanced in v2, mastering is done automatically so that "Prop. 2" becomes large. I think that it will be less time to manually adjust the parameters.
Professionalism 2 (Professionality 2)
"Proposity 2" is an index that improves "Proposity". Added to analytical indicators. We are learning with more data than "Proposity".
Increased upload size upper limit and source length upper limit for PC version
New upload size limit: 250MB (conventional: 150MB)
New sound source upper limit: 15 minutes (conventional: 10 minutes)
Please wait for a while as the iPhone version supports the application side.
Enhanced monitoring to prevent system failures due to unknown causes.
Premium Plan Double Billing
Some people registered for the premium plan were charged twice.
Specifically, if payment for payment fails for some reason while registering for the premium plan, then register for the premium plan again, and then if the payment for the old premium plan is restored, the old premium plan and the new premium plan will be simultaneously Continued and charges were double charged.
We will do the following for those who are eligible. There is no need for customer support. I was very sorry.
A: Canceling the old premium plan
B: Double charge refund
C: In addition to B, as an apology I refunded the most recent one month's worth
Also, I have fixed the program to prevent it from happening again. In the future, we have enhanced monitoring so that we can discover early even if double charges occur due to unknown cases.